
Ever wonder why it’s a best practice for scanned .pdf files to be text-recognized (OCR’d) before they are shared? Let’s look at these two critical considerations. (There are more but I’ll stop at two.)
First. A scanned-only document displays like a picture. It’s an image that you can only look at. You can’t “use” or “work with” the document. You can’t search for key terms, highlight, or copy-and-paste from it.
Second. A text-recognized digital file can be read by text-to-speech apps—in addition to being usable in the ways described above. This means that the same file is also accessible to those with low vision or those who prefer to “listen” to written files. By contrast, a scanned-only file is a dud for digital readers.
Did you know? 2.3% of individuals in the 2018 American Community Survey report a visual disability.
Erickson, W., Lee, C. & von Schrader, S. (2020). 2018 Disability Status Report: United States. Ithaca, NY: Cornell University Yang-Tan Institute on Employment and Disability (YTI).
These differences come into focus when comparing the OCR’d and non-OCR’d versions of a recent federal court opinion. The decision certified a question to the Michigan Supreme Court. I did not manipulate either digital file.
Here’s the digital file as published by the federal court. The OCR’d digital file was most likely created with one click directly from the word-processing program by any of these options:
- “Save as Adobe PDF”
- Print to “Adobe PDF”
- Print to “Microsoft Print to PDF”
- “Publish to PDF”
Notice how you can drag your cursor over the text and highlight portions? Imagine being able to easily copy a portion and paste it onto a different document. You can use the search (magnifying glass) icon in this file and search the document for key terms (such as “Stay at Home”). If you want, you can open the file in a new window, or download it to your computer and run a text-to-speech program. This is a beautiful file.
Fullscreen ModeSwitching digital gears. Now here is the scanned-only version of the paper copy that the Michigan Supreme Court received. The paper opinion was scanned, but not OCR’d, and uploaded to the oral argument section of the Michigan Supreme Court website.
Fullscreen ModeNotice how, on the scanned-copy, you cannot search for terms? No text has been recognized in the file. It’s just pages of images. Nothing else.
You can see (and hear) the differences in action in this short clip. I used the Chrome browser and the Read Aloud Chrome extension as one example of text-to-speech functionality. This clip also demos the Adobe Reader (free) “Read Out Loud” feature.
So how hard is it to “text-recognize” a scanned .pdf file before posting it online, efiling it, or sharing it with others?
It’s one mouse click when using Adobe Acrobat (not the Reader). Just tell Acrobat to “Recognize Text” in the file. Save. Done.
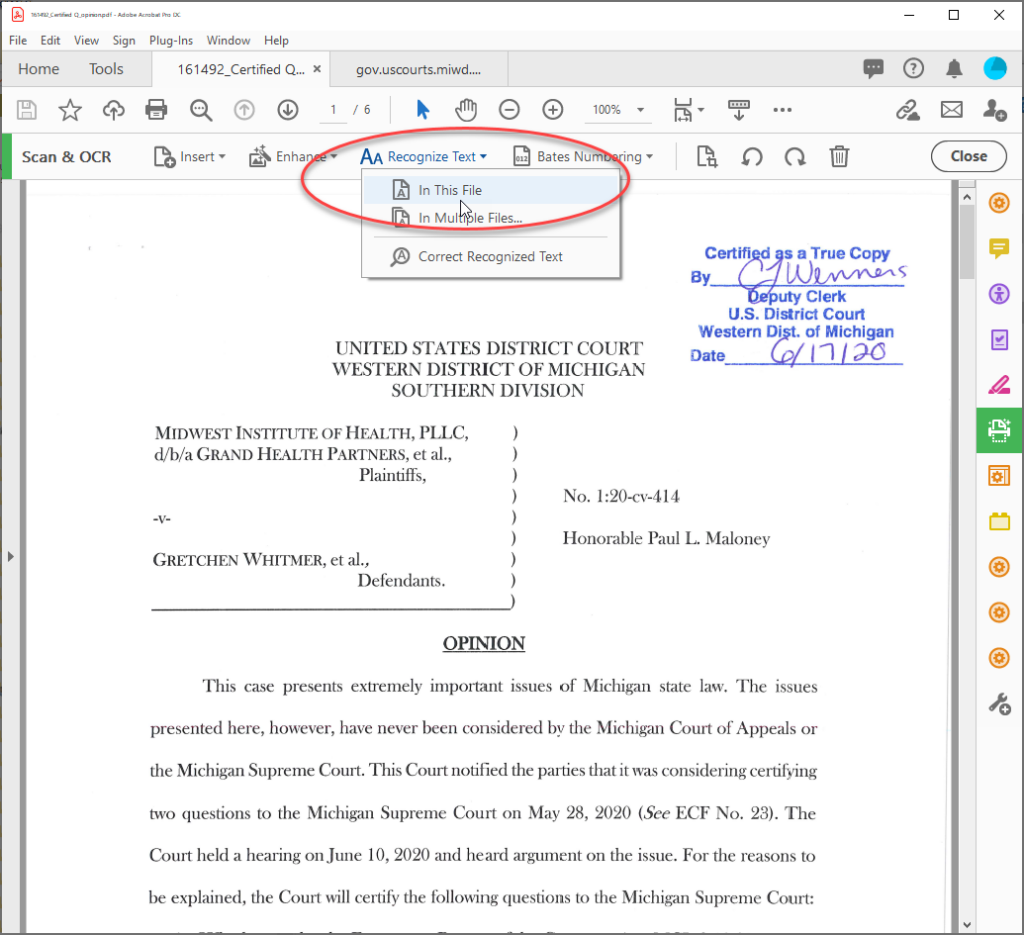
I recommend that you have an Adobe Acrobat license (free trials are available). This is not an advertisement. I receive no compensation from Adobe.
Final thought. Before you share, efile, or upload a .pdf file, make certain that all of its content is text-recognized!
It’s the only way to prepare text-based digital files that are intended to be shared.